Akasha Notifier—Part I
Yet more push notifications for your phone to suppress in the name of aggressive power saving.

A project that started out as simply updating a few contact forms, the code from which is now over a decade old set of php scripts, has turned into a monster overhaul of my server architecture & monitoring thereof.
This post will explore the ins and outs of the backend portion of the solution now implemented for this initial task of contacting me when someone uses a notification form on a website I administer, and soon—in Part II, which should be a lot shorter, we’ll take a look at some frontend implementations. Parts III and IV will take a look at how this system now oversees my infrastructure as well.
Without getting into the specifics of the old scripts, they had two major pros going for them:
- A simple captcha system to mitigate spam
- A php backend that could obfuscate my mailing address for the same purpose
But now, in the future we have things like CVE-2019-11043, and the general annoyance of working with php in the first place. Oh, and push notifications, async–await stabilised and cool new frameworks to learn and a lot of over-engineering to do instead of working on the things you actually should be doing.
🔗Replacing PHP
So literally the only thing I had running on one of my web servers using PHP was a few instances of this contact form. Getting rid of that would require some form of new backend, and I wanted it snappy. A few run-ins with rocket’s synchronous paradigm when spawning off requests to 3rd parties caused me no end of annoyance when actively working on oration. I’d heard that actix-web had solved a bunch of its teething problems, so decided to start with it as a basis.
The last quarter of 2019 was perhaps not the best time to be working on a Rust web app—pretty much everything was in a state of flux as Futures & async/.await stabilised, and libraries either rushed to patch or failed to do so in a timely fashion.
Suffice to say, this codebase undertook myriad revisions to get it to where it stands now.
Actix-web 2.0 thankfully now exists, running on standardised async-await code, although my implementation has a synchronous blocker from redis-rs.
A major PR has been merged in that crate to bring it up-to-date, however I’d prefer to wait for an official release on that rather than relying on a #master dependency.
Anyway, let’s just concern ourselves with the current implementation and what I learnt along the way. My plan here was to provide a full fledged solution that takes on a bunch of edge cases. There’s always some rando on Hackernews spouting about their new ‘Minimalistic’, ‘bare-bones’, ‘streamlined’, ‘no bullshit’ implementation of a can opener or whatever. These projects are MVPs in the absolute minimal of senses, they should probably be calling them ₘVPs. Seldom do these projects have to deal with actual infrastructure questions, so a lot of these problems are seemingly absent from help forums and such online; hopefully I can shed some light on a couple of these issues as we go along for those of you interested in how best to handle them.
🔗The backend
Other than Actix, we’ve got a few more dependencies, but not a whole bunch:
[dependencies]
log = "0.4"
simplelog = "0.7"
failure = "0.1"
failure_derive = "0.1"
actix = "0.9"
redis = "0.13"
actix-cors = "0.2.0"
actix-web = { version = "2.0", features = ["openssl"] }
actix-http = "1.0.1"
actix-rt = "1.0"
base64 = "0.10"
captcha = "*"
serde = "1.0"
serde_derive = "1.0"
uuid = { version = "0.7", features = ["serde", "v4"] }
config = "0.9"
lazy_static = "1.4"
url = "2.1"
Literally a few crates for log handling, error handling, serialisation & configuration.
The only ‘extra’ ones outside of those are captcha, which I use in conjunction with uuid and base64, and redis—which is probably well known to those of you reading this post, but the first time I’ve seen the need to use it.
For the moment, I haven’t made this code public. Initially due to concerns over my plans to be a bit sloppy about personal info scattering the codebase, then due to perceived abuse vectors (which I think I’ve managed to subsequently cover), now for no other reason than I’d have to like, you know, click a few buttons. We’ll go over some of the more interesting portions here, but if you’re interested in seeing more, feel free to get in touch.
🔗Making things async with actix-web
Here’s the main function of the app as it stands:
#[actix_rt::main]
async fn main() -> std::io::Result<()> {
lazy_static::initialize(&SETTINGS);
simplelog::WriteLogger::init(
simplelog::LevelFilter::Info,
simplelog::Config::default(),
std::fs::OpenOptions::new()
.append(true)
.create(true)
.open("/var/log/akasha-notifier/notifier.log")?,
)
.unwrap_or_else(|err| exit_with_message("Failed to initiate logging", &err));
let client = redis::Client::open("redis://127.0.0.1/")
.unwrap_or_else(|err| exit_with_message("Could not find Redis", &err));
let redis_connection = web::Data::new(KVStore {
connection: Mutex::new(
client
.get_connection()
.unwrap_or_else(|err| exit_with_message("Could not connect to Redis", &err)),
),
});
HttpServer::new(move || {
App::new()
.wrap(Logger::default())
.wrap(
Cors::new()
.allowed_origin("http://localhost:8000")
.allowed_origin("https://www.exactlyinfinite.com")
.allowed_origin("https://odyssey.neophilus.net")
// A few more, but you get the point
.allowed_methods(vec!["GET", "POST"])
.finish(),
)
.wrap(Compress::new(ContentEncoding::Br))
.app_data(redis_connection.clone())
.service(web::resource("/captcha").route(web::get().to(get_captcha)))
.service(web::resource("/contact").route(web::post().to(process_contact_request)))
})
.bind("127.0.0.1:7361")?
.run()
.await
}
Legit, this is all we need to do to pull settings in from a file, get a log running, connect to a redis instance for storing in-memory data and asynchronously serve up the app end points with Brotli compression & a functioning CORS policy!
We’ll jump into specifics a little later, but let’s talk about the two end points for a moment so you get the gist of what we’re trying to achieve.
🔗/captcha
Here, we allow a GET request to a function with a type signature of
async fn get_captcha(
req: HttpRequest,
kv: web::Data<KVStore>
) -> Result<HttpResponse, Error>
which has a few tasks it needs to handle. Ultimately, we need to return a captcha image and keep track of all active sessions and their associated challenge values.
After verifying an active connection to the redis client, we check req.headers().get("session") and generate a new uuid if one doesn’t exist—this differentiates a new session or a request from the front end to refresh the current captcha.
Then, captcha generation comes from a portion of the captcha crate.
It’s a fairly all-in-one library with its own API, but hasn’t been updated in 3 years and much of the edge cases I wanted to get into in this post are just not handled by it.
So we use a very small portion of the library to generate an image and challenge value:
fn generate_challenge() -> Result<(String, String), Error> {
let mut captcha = Captcha::new();
captcha
.add_chars(5)
.apply_filter(Noise::new(0.3))
.apply_filter(Wave::new(2.0, 20.0))
.view(180, 100)
.apply_filter(
Cow::new()
.min_radius(40)
.max_radius(50)
.circles(1)
.area(Geometry::new(40, 150, 50, 70)),
);
let (value, image) = captcha.as_tuple().ok_or(NotifierError::CaptchaGeneration)?;
let b64 = base64::encode(&image);
Ok((
format!("data:image/png;base64,{}", b64.replace("\r\n", "")),
value,
))
}
Which yields something like the image below.
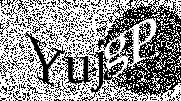
Note that we return a base64 encoded string here, the reason for this is two-fold.
- We can insert the
data:value directly into thesrctag of an image handle at the front end via javascript (ultimately from Elm, which we’ll look at in Part II). - We don’t want to cache such an image, thus its beneficial to send strings across the wire rather than adding exceptions to the caching rules of your web server.
All this activity is logged, we store the challenge value against the session uuid in redis (with an expiry time), then return the image in a plain text response body with the session value attached as a header.
🔗/contact
A POST request to /contact expects a JSON payload (for the moment: considering further over-engineering here and using gRPC. Perhaps see Part V—overhauling an already well functioning system?) that deserialises into the ContactRequest struct—essentially just a bunch of strings for name, email, message etc.
async fn process_contact_request(
contact_request: web::Json<ContactRequest>,
req: HttpRequest,
kv: web::Data<KVStore>,
) -> Result<HttpResponse, Error>
This method has a few checks that must pass before anything else happens
- A redis connection must be active
- A session header must be present
- The session / challenge key / value must be retrieved from redis
- The challenge must be correct
Each of these events return some form of failure to the frontend if they occur, otherwise a 200 OK is sent to indicate success.
The active portion of this method sends off a structured message to a Telegram bot I control. There are plenty of tutorials on the net on how to do this, this one is as good as any.
async fn report_to_akasha_notifier(
contact: &ContactRequest,
referer: &str,
remote: &str,
) -> Result<(), Error> {
let mut request = String::from("https://api.telegram.org/bot");
request.push_str(&SETTINGS.get::<String>("bot_token")?);
request.push_str("/sendMessage?parse_mode=HTML&chat_id=");
request.push_str(&SETTINGS.get::<String>("conversation")?);
request.push_str("&");
// Website is optional, so we wrap it up here
let website = if contact.website.is_empty() {
String::new()
} else {
["\n<b>Website:</b> ", &contact.website].concat()
};
// Subject is similar: we don't use it on all contact forms.
let subject = if contact.subject.is_empty() {
String::new()
} else {
["\n\n<b>Subject:</b> ", &contact.subject].concat()
};
let encoded_text = form_urlencoded::Serializer::new(String::new())
.append_pair(
"text",
&format!(
"Message posted on {} from {}\n\n<b>Name:</b> {}\n<b>Email:</b> {}{}{}\n\n{}",
referer, remote, contact.name, contact.email, website, subject, contact.message,
),
)
.finish();
request.push_str(&encoded_text);
let client = ClientBuilder::new()
.timeout(Duration::from_secs(10))
.finish();
// We currently don't care about the response, so long as we don't get a timeout.
// NOTE: This will silently fail on XSS attempts and give a success response to the client.
// Unsure if this is a good or bad thing at the moment - we need to monitor abuse.
let _ = client
.get(&request)
.send()
.await
.map_err(|error| error!("Could not send notification to Akasha Bot: {}", error));
Ok(())
}
I’ve externalised bot_token and conversation here into a settings file on the off chance this code is ever released publicly.
As you can see, most of this function is forming a request string, then finally uses an actix client to send an async get request to the Telegram API.
Surprisingly, I didn’t manage to find anyone explicitly using this method online for simple requests.
Most end up bundling another crate like reqwest, but if you’re already using actix-web, why not stay in the same ecosystem?
🔗Security & Performance concerns and fixes
Alright, so with the basics of the backend covered, this section is the one you really want to pay attention to. Most of these questions I’ve managed to now answer at least somewhat through my investigations, but would appreciate any additional info you guys have managed to come across in your travels too.
🔗How should I deploy this app securely, and why don’t people use SSL in production?
So, it’s possible with actix-web to bind a port over https via either the hosts’ openssl or rustls.
I could add the following to my main() (with some appropriate error handling of course):
let mut builder = SslAcceptor::mozilla_intermediate(SslMethod::tls()).unwrap();
builder
.set_private_key_file("/path/to/privkey.pem", SslFiletype::PEM)
.unwrap();
builder.set_certificate_chain_file("/path/to/fullchain.pem").unwrap();
// ...
// Replacing the ".bind("127.0.0.1:7361")?" line of the HttpServer block:
.bind_openssl("www.neophilus.net:7361", builder)?
with this, I can call https://www.neophilus.net:7361/{captcha|contact} over http/2.0 on either the IPv4 or IPv6 network.
Sounds great! So why am I ultimately using the insecure bind method and this reverse proxy block in my nginx config?
location /notify {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_http_version 1.1;
rewrite /notify/(.*) /$1 break;
limit_req zone=one burst=3 nodelay;
proxy_pass http://127.0.0.1:7361;
}
Well, the first point is that when you bind a port, you can’t use that again for another application.
So if nginx is already running on 80/443, your little notification system can’t use them.
Is it so much of an issue having another open port?
Maybe not, but generally it seems cleaner to have an end point at /notify/ rather than :7361/.
Thus, I was searching around forever trying to find a way to deploy a web app via an nginx reverse proxy but in a secure manner with the features listed above (http/2.0 and both IP versions).
Turns out this isn’t really that necessary or useful.
Certainly, there are ways to secure upstream traffic, but as they say in that article, there are now additional & expensive SSL handshakes to contend with—which may be a price you’re willing to pay if your upstream is on another machine. But locally? You can see the two backend example severs use insecure local endpoints…
The thought process here is that the secure communication layer is for transport of requests from your server to a client. Communication within your system, to the client, is essentially opaque since they only really view the ‘edge’ of your server in the first place. The SSL layer is therefore soley there to mitigate man-in-the-middle and on-the-wire attack vectors, but cannot address hostile events within a hacked or bad-actor machine. So, harden our machines to mitigate attacks, and so long as we keep them that way; unsecured communication within them is fine as far as some external client is concerned.
But herein lies our next issue: if we don’t use SSL, we can’t connect to our web app via http/2.0—SSL is a pre-requisite!
Damn! But think about it: the reason why http/2.0 improves performance over http/1.1 is multiple dispatch. Multiplexing a bunch of requests into one rather than a queue of single request/response cycles. The reason this method is superior is time-of-flight between the client and server, but if we’re considering communication between one web service on our machine to another on the same hardware, then time-of-flight is effectively zero. All of the bennefits of http/2.0 are therefore not required after we hit the server edge—another moot point.
Finally, we come to the IP version question: are we only going to accept IPv4 connections in this way? Well, yes, internally since we provided a v4 proxy address. But again, this is only internally. Nginx is now handling everything to the edge—http/2.0, IPv4/6, SSL, correct routing etc etc. Our app can remain straightforward and direct, no need to punch another hole in our firewall and have some obsure port visible.
This solution answers all of my questions regarding secure deployment: keep your nginx system hardened and flexible, and your proxies simple (until someone can explain to me why this is a completely stupid idea).
🔗CORS doesn’t seem to do anything really useful? I can spoof most of this…
Since I was testing my API with curl, the CORS policy I was setting initially seemed a little useless. Maybe I don’t want everyone to be able to just call
curl https://www.exactlyinfinite.com/notify/captcha
as they please.
Ah!
I can add a CORS policy to only allow my domains to access the script.
But wait? I did that and the curl request still works?
Oh, you must check against the Origin header, so lets force the client to send this header all the time:
web::resource("/captcha")
.route(
web::route()
.guard(guard::fn_guard(|req| !req.headers().contains_key("origin")))
.to(|| HttpResponse::MethodNotAllowed()),
)
.route(web::get().to(get_captcha)),
Sweet, and of course you can do this using curl via
curl -H "Origin: https://www.exactlyinfinite.com" https://www.exactlyinfinite.com/notify/captcha
Oh. But this was the thing I wanted to avoid…
So this isn’t really that helpful is it?
Well, yes it is, but not for this specific problem.
You see, in the browser, Origin is a protected header.
Spoofing it can be done only when you really really want to, a general user wont have the extensions to do this and therefore an attempted hijack of your resources by a 3rd party is generally thwarted by a locked down CORS policy.
🔗How should I handle people hijacking or attacking my implementation?
CORS is certainly one way of dealing with hijacking, as is having an API design that makes it fairly opaque how to use the system if you’re not wanting others to do so. Here for example, generating captchas without any ability to verify them simply isn’t that helpful to a 3rd party looking to steal your bandwidth and CPU cycles.
Having no obvious contact end point anywhere mitigates another vector of misconduct. For example you can find email addresses in my old php script versions if you search deep enough into the published code, which isn’t the best. Here, you know it’s Telegram, but have no idea of my BOT details or conversation ID.
With all of that, DoS is the next vector one should consider. If people can’t use it, they sometimes like to trash it. Computing images and storing session/challenge data is a better end point to focus on in a DoS attack rather than some other request since it’s CPU, Memory and network bound.
This post is already way too long, so here’s my solution to this issue:
As you’ve seen above, there was a line limit_req zone=one burst=3 nodelay; in my proxy block.
Pair this with
limit_req_zone $binary_remote_addr zone=one:5m rate=30r/m;
in your http block and you’ve set up a rate limit on your notifier system.
We’ll use 5MB of memory here, which should be good to store 80,000 IP addresses (maxing out that number is a DoS attack for which I’d be flattered by); limiting each user to two requests a second—although a burst of three retries is allowed.
On the front end, users are given a notice to calm down a little once they receive the 503 response; but for something more sinister, we add this lovely little fail2ban block in /etc/fail2ban/jail.local:
[nginx-req-limit]
enabled = true
filter = nginx-req-limit
action = iptables-multiport[name=ReqLimit, port="http,https", protocol=tcp]
logpath = /var/log/nginx/*error.log
findtime = 300
bantime = 7200
maxretry = 25
Clients that hit the rate limit 25 times over a 5 minute period get shut out of the server for two hours.
You’ll need this filter file to make it work: /etc/fail2ban/filter.d/nginx-req-limit.conf
# Fail2Ban configuration file
#
# supports: ngx_http_limit_req_module module
[Definition]
failregex = limiting requests, excess:.* by zone.*client: <HOST>
# Option: ignoreregex
# Notes.: regex to ignore. If this regex matches, the line is ignored.
# Values: TEXT
#
ignoreregex =
🔗Summary and Outlook
There was a surprising amount of not-so-clear implementation questions for me on this one—not so much the how, but more the why. Of course, there are always some new tid-bits to learn, for example this function:
fn exit_with_message(message: &str, error: &dyn std::error::Error) -> ! {
::std::process::exit({
eprintln!("{}: {:?}", message, error);
1
});
}
Did you know you can return nothing with ! rather than returning the default identity ()?
Additionally, this was the first time I have ended up using a trait as an argument, so that was nice.
Anyhow, hopefully some of this ends up helping you out when configuring your own apps one day.
Stay tuned for Part II soon, where we’ll checkout some specifics of the frontend, then following sometime after that we explore how we can extend this notification idea to monitor our entire server infrastructure.